
Alright, so your big data infrastructure is up and running. You’ve collected and analyzed gigabytes, terabytes, maybe even petabytes of data and now you’d like to visualize your data on desktop PCs, tablets, and smart phones.
How do you go about doing this? Well, let me show you. Visualizing big data, in many cases, isn’t far from visualizing small data. At a high level, big data when summarized/aggregated, simply becomes smaller data.
In this post, we’ll focus on transforming big data into smaller data for reporting and visualization by discussing the ideal architecture, as well as present a case study.
Architecture: Frontend (data visualization)
On the front end, we utilize responsive design with a single code base to support desktop, tablet, and mobile phones. For native mobile apps, we can utilize tools like PhoneGap or Adobe Cordova for responsive design; a process that significantly cuts down cost, shortens time to market, and is a great option for business apps.
Here are two popular frontend approaches:
1. Server Side MVC:
Server side MVC (model view controller) has been the de facto standard for web app development for quite some time. It’s mature, has a well established tool set (i.e Ruby on Rails), and is search engine friendly. The only downsides are it’s less interactive and less responsive.
2. Client Side MVC:
Capitalizing on JavaScript for page rendering, apps developed on Client Side MVC are more responsive and interactive than server versions. At Intridea, we’ve found this method to be particularly suited for interactive data. In addition, referred to as single page applications, Client Side MVC, have the look and feel of a desktop app. Therefore, creating an ideal user experience that is highly responsive and requires minimal page refreshing.
Architecture: Backend (data storage and processing)
Typically ‘big data’ is collected through some kind of streaming APIs and stored in HDFS, HBase, Cassandra, or S3. Hive, Impala, and CQL can be used to query directly against the data. It’s fairly convenient to query big data this way, however not efficient if data has to be queried frequently for reporting purposes.
In these situations, extracting aggregated data into smaller data may be the better solution. MongoDB, Riak, Postgres, and MySQL are good options for storing smaller data. Big data can be transformed into smaller data, using ETL (Extract, Transform, Load) tools, thus making it more manageable (e.g. realtime data can be aggregated to hourly, daily, or monthly summary data).
Note: For single page application, a restful API server is needed to access the aggregated data. Our favorite API Server is Ruby on Rails.
Case Study: American Bible Society
American Bible Society provides online access to 582 versions of the Bible in 466 languages through partnerships with publishers. With their javascript API generating billions of records every year, ABS needed help making sense of their data. Thus, we partnered with ABS to create ScriptureAnalytics, a site that gives insights into their vast collection of data.
Access to the Bible translations was provided via JavaScript APIs. The usage of the APIs was tracked at the verse level, along with ip location, timestamp, and duration. The raw usage data was collected through AWS Cloudfront (Apache log files) and stored on EC2 S3 and preprocessing/aggregation of stats was conducted via AWS Elastic Map/Reduce with Apache Pig and Hive.
ABS receives over 500 million tracking log entries from Cloudfront every year, including several bible verse views per entry. What’s this amount to annually? About several billion views each year!
Intridea was asked to develop public and private dashboards for visualizing Bible readership stats in an interactive and responsive way. The public dashboard, scriptureanalytics.com, was developed for the general public to view summary level status and trends. While the private dashboard was for ABS and publishers to track individual translations, helping them be strategic on a multitude of levels.
The dashboards were developed as a responsive single page app with Rails/MongoDB as the backend, and Backbone.js, D3, Mapbox as the frontend. The app pulls aggregated hourly/daily stats (generated using Hive and Pig running on Elastic Map/Reduce Hadoop clusters against the raw data stored in S3) in the JSON format from S3 and stores them in MongoDB for fast query access. The dashboards pull data from MongoDB via Rails and use Backbone/D3/Mapbox to visualize the stats. We use MongoDB’s aggregation framework to query the data stored in MongoDB.
See screen shots below for iOS, iPad, and desktop PC:
Smart Phone
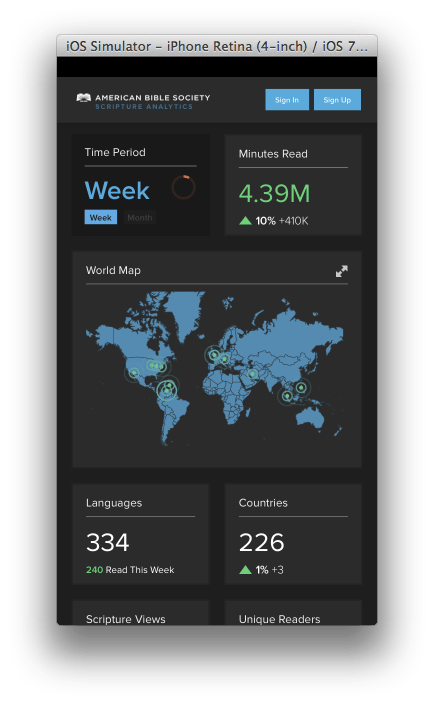
Tablet
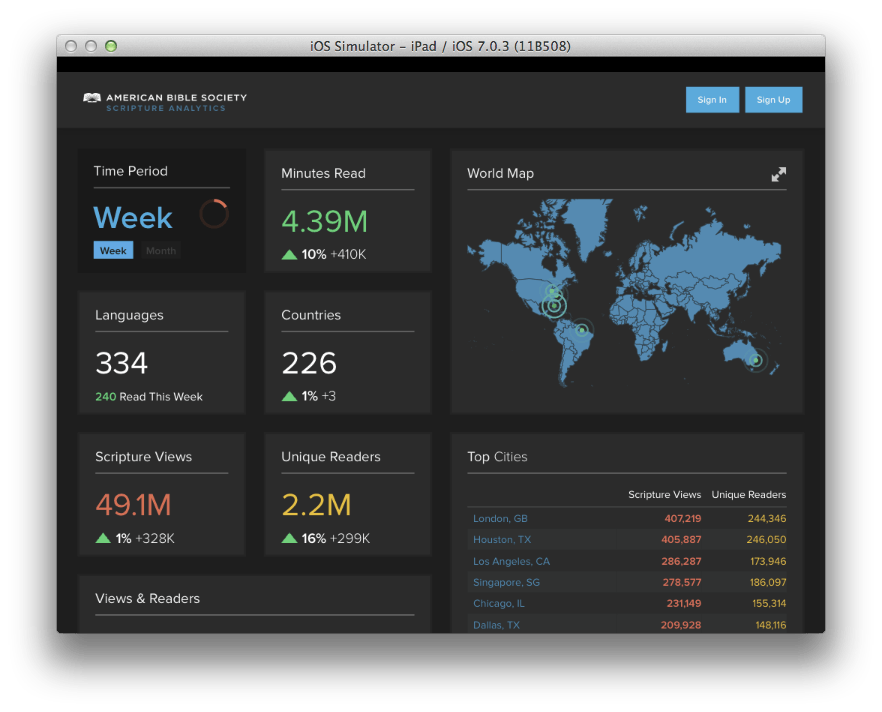
Desktop
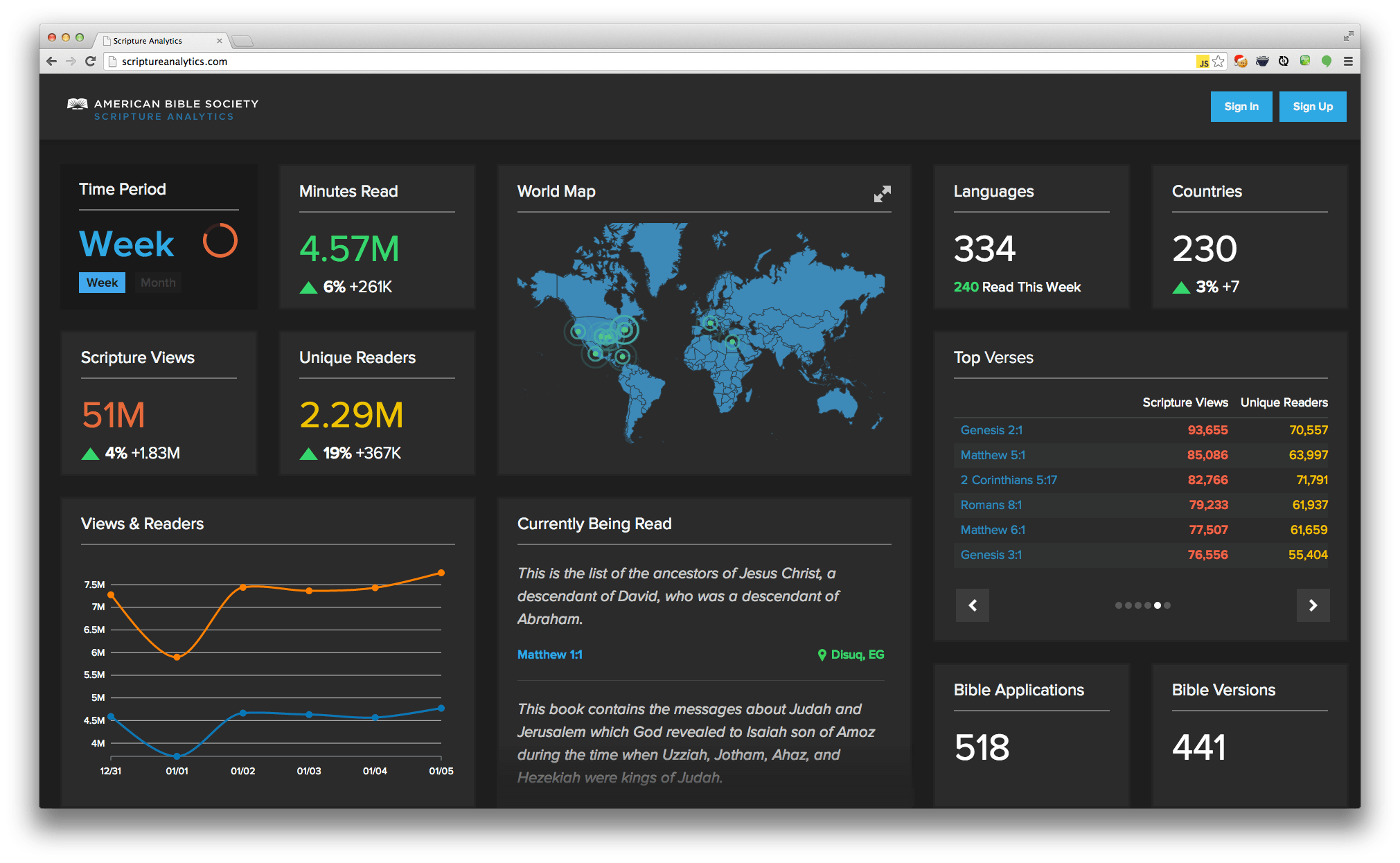
Got any questions about visualizing big data on a small screen? Let us know!
Want to learn more? Check out the entire Big Data series below!
- Big Data, Small Budget
- Single Page Apps: Popular Client Side MVC Frameworks

